
CLASSES ↑ beginner to advanced ↓
CONVERSION RATE ACADEMY
Avoiding False Positives: Statistical Pitfalls
It’s tempting to celebrate when you see an uplift, but premature conglutination can lead you down the wrong path. Avoiding statistical traps is essential to running trustworthy experiments.
Start With the Right Goal
If the goal is weak, the test result is meaningless.
Use goals tied to business outcomes:
- Purchases
- Qualified leads
- Trial starts
- Revenue
Avoid optimizing for clicks, form starts, or engagement unless they directly represent success.
Understand Confidence
Confidence measures how likely the result is real. There are a few statistical models, but all of them work roughly the same way, in that the data is a representation of the current data levels accuracy,.
Low confidence = high chance the outcome is random.
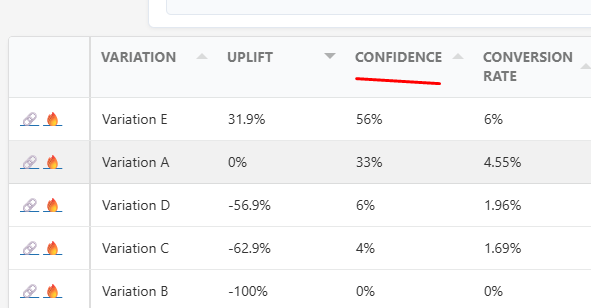
Do not declare a winner until confidence reaches your predefined level. Best practice suggest 95% confidence.
Let the test reach those thresholds before making a decision.
- Minimum sample size (at least 100 visits to each variation)
- Required confidence level (95%)
- Minimum runtime (1 week or 1 month)
What Is a False Positive?
A false positive is when a variation appears to win due to randomness rather than a real improvement.
Small sample sizes often create temporary lifts that disappear as more data is collected. False positives happen when you make a decision and the confidence is below 95%
Don’t Stop Tests Early
The most common mistake is ending a test after seeing an early uplift. Same as false positives – while the results may be correct, it’s too early to be sure. Don’t guess, just wait for the data to collect.
Multiple Variations, longer tests
Testing many variants increases the chance that one looks like a winner by luck. Stronger evidence is required before acting which makes tests take longer to reach a strong confidence level.
The AB Split Test plugin helps mitigate these risks by tracking confidence levels and only declaring a winner when the uplift is statistically significant. Its dashboards encourage you to run tests through completion and show sample sizes for each variant. Combine these safeguards with disciplined testing habits – set hypotheses, define success metrics and commit to minimum run times – and you’ll avoid false positives and build a reliable optimization program.